Foundations of Deep Learning and Neural Network Optimization
MIT Introduction to Deep Learning covers the foundations of deep learning and AI, showcasing generative deep learning advancements. Learn about neural networks, backpropagation, and training algorithms. Optimize networks to avoid overfitting with regularization techniques.
00:00:09 MIT Introduction to Deep Learning is a fast-paced program that covers the foundations of deep learning and AI. It showcases the advancements in generative deep learning and its applications in various fields. The course provides a solid foundation through lectures and hands-on software labs.
MIT Introduction to Deep Learning is a fast-paced program that covers the foundations of deep learning and AI.
Deep learning has seen significant progress, with the ability to generate synthetic data and even software.
The course includes technical lectures and hands-on software labs to provide a solid foundation in deep learning.
00:08:36 Learn about deep learning in the MIT Introduction to Deep Learning course. Build neural networks, generate music, and pitch deep learning ideas for a chance to win prizes.
📚 The course includes dedicated software labs and a project pitch competition where participants can present novel deep learning ideas.
💻 Prizes for the competition include an Nvidia GPU and a grand prize for solving challenging problems in deep learning.
⚙️ Deep learning uses neural networks to extract patterns from data and make decisions based on those patterns.
📈 Advances in data availability, compute power, and open-source software have made deep learning more accessible and powerful.
00:17:07 This video explains the use of non-linear activation functions in deep neural networks and introduces the concept of perceptrons and their propagation of information.
🧠 Nonlinear activation functions like the sigmoid and ReLU are important in deep neural networks as they introduce non-linearities to capture patterns in real-world data.
🔀 The forward propagation of information through a perceptron involves multiplying inputs with weights, adding a bias, and applying a non-linear activation function.
🧩 By combining multiple perceptrons, a neural network can be built to handle complex data and generate outputs based on learned patterns.
00:25:38 This video explains how to define the forward propagation of information in deep learning and how to stack multiple layers to create a deep neural network. It also discusses how to train a neural network using a loss function.
🧠 Forward propagation is the process of transforming inputs into outputs in a neural network.
🔗 Neurons in a neural network receive inputs, apply weights and biases, and output results through a non-linear function.
🧱 Neural networks can be stacked to create deep neural networks, where each layer is fully connected to the next.
00:34:07 MIT introduces the concept of cross-entropy and mean squared error loss in the context of training neural networks. They discuss gradient descent and backpropagation as key algorithms for minimizing loss.
🔑 Cross-entropy loss is used to train neural networks and was developed at MIT.
📊 Mean squared error loss is used for predicting continuous variables in neural networks.
🔍 Gradient descent is an algorithm used to find the optimal weights that minimize the loss function in neural networks.
⚙️ Backpropagation is the process of computing the gradients of the loss function with respect to the weights in a neural network.
00:42:34 Summary: The video covers the backpropagation algorithm and the challenges of training neural networks, including setting the learning rate. It discusses the concept of adaptive learning rate algorithms and the benefits of batching data into mini batches. Title: MIT Introduction to Deep Learning | 6.S191.
🔑 The back propagation algorithm is the core of training neural networks.
🔎 Optimizing neural networks is challenging due to the complex landscape and the selection of the learning rate.
📈 Using mini-batches in training neural networks improves computational efficiency and gradient accuracy.
00:51:03 Learn how to optimize neural networks to avoid overfitting. Topics covered include regularization techniques such as dropout and early stopping.
📚 Regularization techniques, such as Dropout and early stopping, are essential in preventing overfitting in neural networks.
💡 Dropout randomly selects and prunes a subset of neurons during training, forcing the network to learn from different models and capturing deeper meaning within the pathways.
⏹️ Early stopping allows us to monitor the performance of the network on a held-out test set and stop training at the point where overfitting occurs.
You might also like...
Read more on Science & Technology
STEAM + Project-Based Learning: Real Solutions From Driving Questions

AMVAC’s Bob Trogele Interviews Pacific Agriscience’s CS Liew About M&A Activity

Steve Harvey / لهذا السبب عليك أن تستيقظ باكرا
macOS Sonoma Released - What's New? (100+ New Features)

Build your Brand with Tactical, Strategic, and Epic content (with Robin Daniels and Warren Daniels)
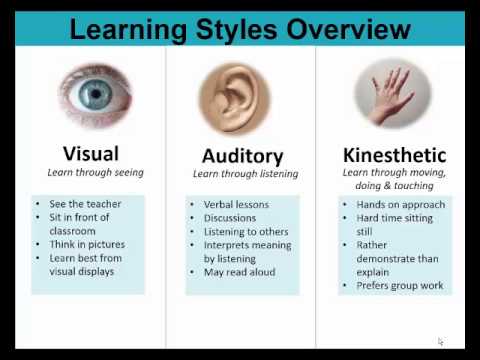
Learning Styles (Preferences) VAK
